Ask Atlas
2026
An LLM-powered content discovery layer for a 1,000-item enterprise data catalog.
Plain-language query in. Specific named report out. Built and deployed end-to-end.
1,000+ catalog items · 4 weeks solo · 3 query paths
Scenario
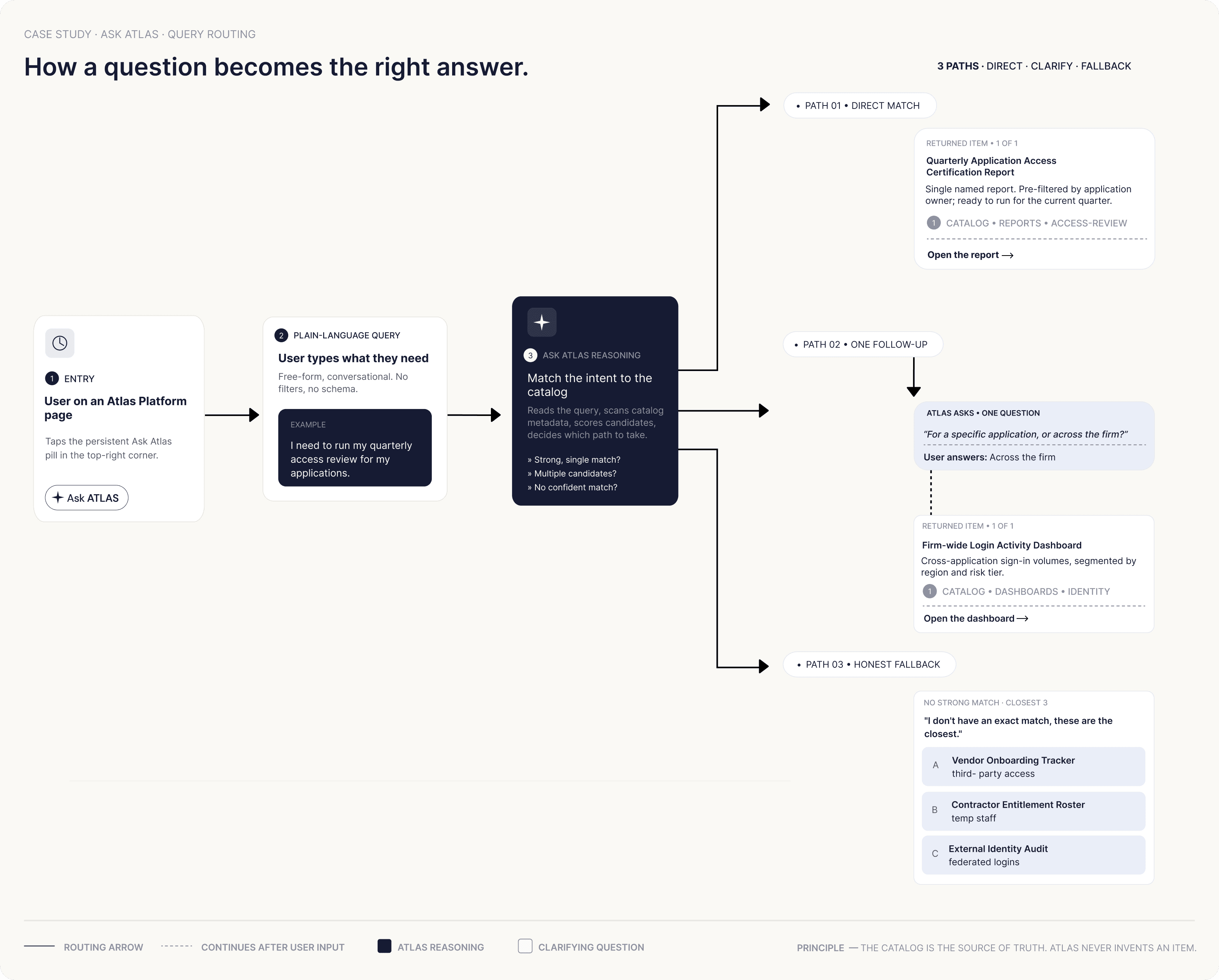
The hero scenario, in action
The most common task Ask Atlas handles is the quarterly access certification — every application owner reviewing who has access to their applications, re-certifying the right people, and revoking the rest. It happens every quarter, across every line of business, and it’s the highest-volume recurring task in the entire IAM program.

The named report, surfaced in seconds. In the live prototype, the report itself stays behind enterprise access controls — Ask Atlas points to it; it doesn’t open it. No catalog hunting, no guess-and-check.
This is the behavior the case study is built around: Ask Atlas returns named, specific content — “the Quarterly Application Access Certification Report,” not “a compliance report.”
Specificity is what separates a discovery tool from a chatbot.
Approach
Why an LLM was the right answer
The catalog had 1,000+ items in vocabulary users couldn’t predict. The question wasn’t whether to fix discovery — it was how.
A better keyword search was the obvious first move. But even a perfect search bar still requires the user to know what to type. The vocabulary gap doesn’t close; it just gets a nicer front door.
A decision-tree wizard came next. Guided flow, predictable outcomes, no AI risk. But a static tree mapped to 1,000+ items breaks the moment the catalog changes — add a report, retire one, the tree’s out of date.
A conversational LLM layer was the third option, and the one I chose. It bridges the vocabulary gap natively, scales with the catalog instead of fighting it, and gets better as users teach it how they actually ask.
Static IA decays. An LLM compounds.
The Problem
The problem self-service created

Scope
What Atlas does - and what it deliberately doesn’t.
Picking an LLM as the approach made the next question more important, not less: what should it actually do?
Ask Atlas is a discovery layer. Plain-language query in, specific named catalog item out. That’s the whole job. It searches catalog metadata — names, descriptions, tags, ownership — and points users to the right thing. When the ask is ambiguous, it asks one focused follow-up. When there’s no confident match, it returns the three closest options and says so honestly.
Everything else was a deliberate cut.
Ask Atlas doesn’t generate reports or dashboards — it points to ones that already exist. It doesn’t write SQL or build queries. It doesn’t run anything on the user’s behalf. It isn’t a decision tree wearing a chat interface, and it isn’t an agent. Each of those was a real option on the table, and each was a confident no.
Scope discipline is what makes an AI feature trustworthy. The line stops at discovery - and it stops there on purpose.

Process
Three surfaces, one designer’s hand on the wheel
I built Ask Atlas solo, in four weeks, end to end. The leverage came from three AI surfaces, each one used for what it’s actually good at.
Claude.ai was the thinking partner — problem framing, scope, the hero scenario, the principles that would govern Ask Atlas’s behavior. Strategy got pressure-tested in conversation before it became a constraint downstream.
Claude Design was where the system came to life — tokens, components, sample conversations, hi-fi prototypes. The brief went in. A working design system and interactive conversational surface came out.
Claude Code shipped the build — React wired to the Claude API, rate-limited, deployed behind a public URL. I had not written code before this project. By the end, I had a live, working AI assistant at askatlas.vercel.app.
Tools shifted. The judgment didn’t.

Prototype
Ask Atlas live prototype
Reflection
What I learned, what’s next
The discipline that mattered most was scope — every cut on the deliberate-no list made the thing Ask Atlas does do more trustworthy. The muscle the project built was unexpected: I thought I was learning to ship code, but what I actually learned was how to write strategy clearly enough that anyone — teammate, contractor, or AI tool — could build directly from it. Phase 2a is what shipped. Phase 2b is deeper retrieval, reading inside the catalog items. Phase 2c is agentic — running the report on the user’s behalf, not just pointing to it.
Ask Atlas is a working prototype built using AI tools and is grounded in enterprise design and product work I’ve completed at scale. The strategic framing, design decisions, prototype, and writing are my own.